- Quality of your training data
- Large language model (LLM) selection
- Explicitness of base prompt
Chunk splitting
During RAG, chunks are selected and injected into the user’s original input query, along with the base prompt. These chunks are derived directly from your uploaded training data - PDFs, Word, websites, TXT files, etc. Since LLMs have token limits, we must also enforce constraints on the size of these chunks. This means that even if your original document has a long chapter of text that talks about a single topic, it will have to be divided into multiple chunks and stored separately within our vector database. So how can we divide up the document with minimal alterations to its original meaning? Unfortunately there is no universal solution. This is still an ongoing field of scientific research. GPT-trainer uses a combination of rule-based and statistical relevance algorithms to divide training data into chunks, but we cannot always guarantee each chunk is self-contained, clean, and accurate. Fortunately, LLMs specialize in working with unstructured text, and they have high tolerances for badly formatted input when producing responses.Chunk quality
Another source of error comes from the chunk content itself. Optimally, each chunk should be self-contained, semantically self-consistent, and grammatically correct. If document structure is important, each chunk should also have relevant metadata specifying where in the document it comes from. However, none of this can be guaranteed when chunks are initially extracted from uploaded text. This error is especially pronounced when working with websites. Since web browsers render websites very differently from how web scraper sees them, what you see can be very different from what our scraper captures. Furthermore, most layout information and data residing in images / illustrations / videos are lost during the scraping process.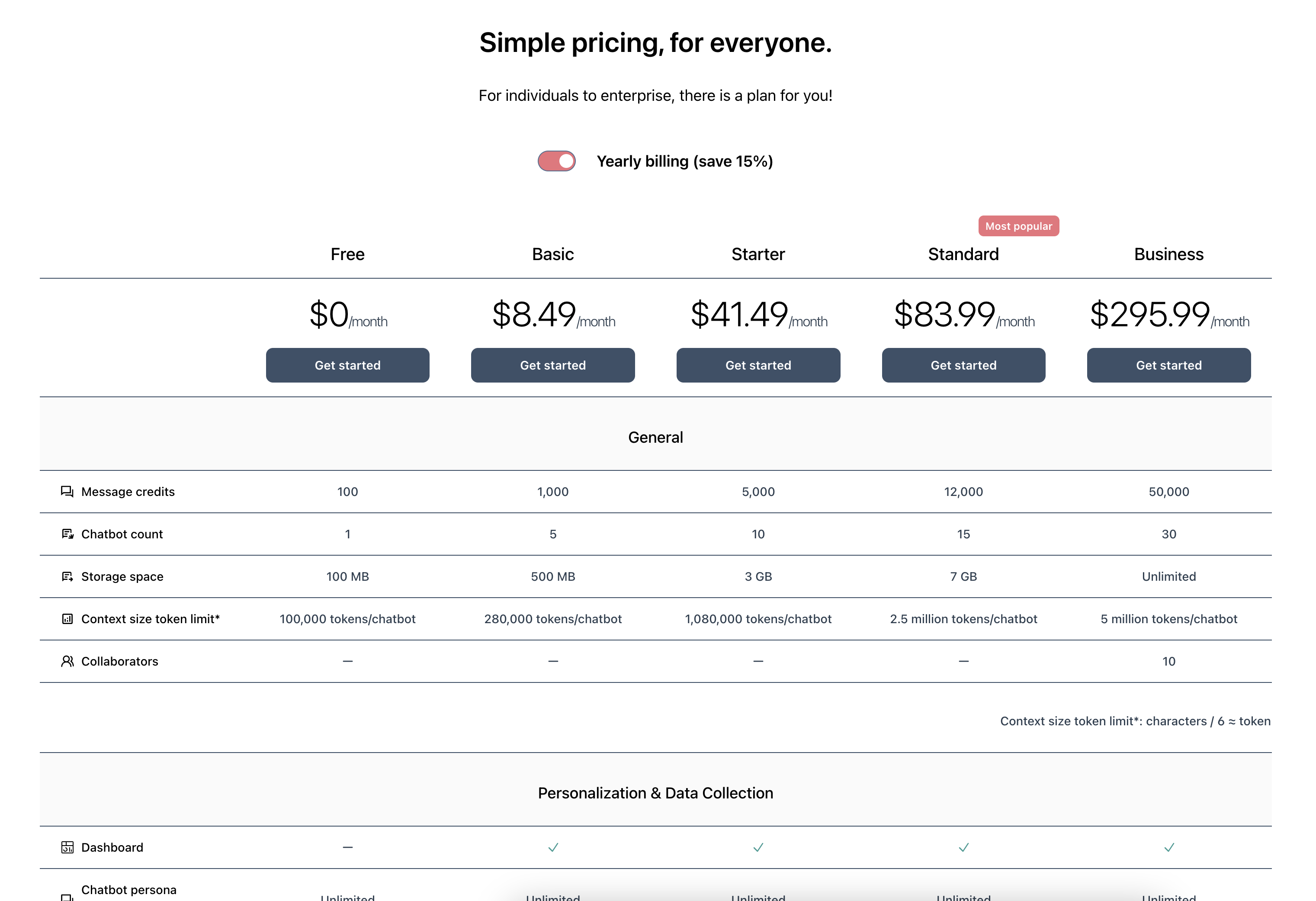
No gaps, no overlaps
RAG relies on dynamically fetching a subset of reference data from the entire collection of training materials. To identify which chunks contain the most relevant information, the user query goes through the same embedding process as the chunks themselves. Then, we calculate a relevance score for every chunk based on the proximity of their embedding vectors relative to the user’s input (cosine distance). Afterwards, the chunks are ranked, and our algorithm picks the top n chunks that can fit into the reserved token window for the chosen LLM. Since the algorithm tries to discover and fit as many relevant chunks as possible, there is the possibility that chunks containing semantically similar, but factually inconsistent information are simultaneously injected into the reference context of the LLM call. For example, if the user asks: What is the price of iPhone SE? then, the algorithm may pull the following chunks to serve as reference context:[Chunk 1] iPhone SE’s current price is $250. [Chunk 2] Original iPhone SE is $199. [Chunk 3] iPhone 5’s price is $600.As you can see, these chunks all explicitly mention the price of iPhone SE, so they are semantically similar to the user’s original query. However, they contain factually inconsistent information. When this happens, you may notice the AI generating different responses each time even if the same question was asked. To ensure better consistency, we recommend that you adopt a “MECE” approach when uploading your training data. MECE stands for Mutually Exclusive, Collectively Exhaustive. In other words - no gaps, no overlaps. If your training data is structured in this way, then you minimize the chances of conflicting information being fed to the LLM during RAG, thereby ensuring that your chatbot behaves in a more predictable and intended fashion.