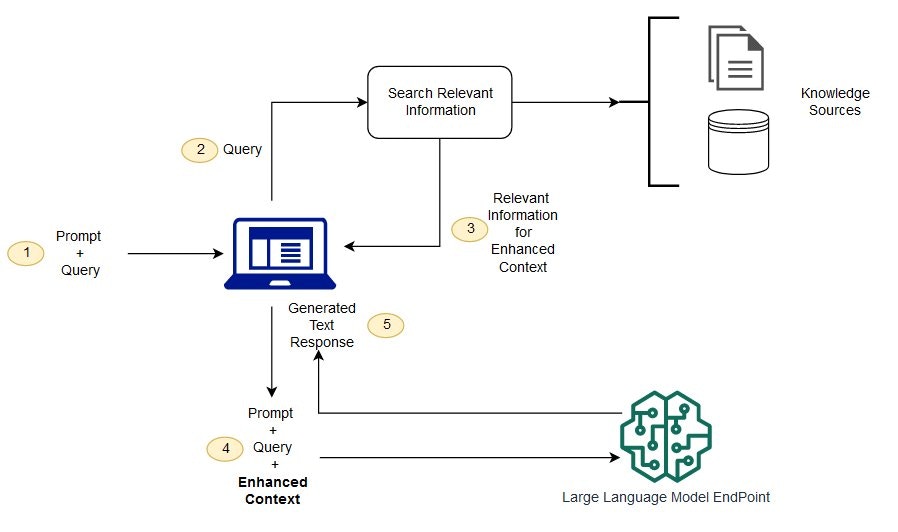
What is Retrieval Augmented Generation (RAG)?
Large Language Models (LLMs) are trained on enormous amounts of text data. Based on this data, the LLM will identify patterns and try to replicate them during its own text generation. When producing an output, LLMs start from a user-written prompt, then algorithmically assigns probabilities to “tokens” or words that most likely succeed (follow after) the prompt based on patterns observed within its original training data. This is why OpenAI named a number of its API endpoints “Chat Completions” - the model tries to “complete” the user’s input query.To better understand what “tokens” are in the context of LLMs, please refer to
the following article from OpenAI’s own documentation:
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
| Query Type | Definition | Example |
|---|---|---|
| Information Retrieval | Asking for specific information residing within one or more documents | ”What is Paladin Max, Inc.’s PTO policy?” |
| Topic-centric Summarization | Aggregating information centered around a theme or topic | ”Summarize the latest developments in generative AI” |
| Query Type | Definition | Example |
|---|---|---|
| Document Comparison | Comparing documents without an explicit criteria | ”Find any inconsistencies across the arguments presented across my documents and list them.” |
| Counting or Math | Counting mentions or performing quantitative analysis based on document content | ”How many times was John named across the contracts?” |
| Meta-Level Instructions | Directing the AI to trace document structure or reference content on specific sections or pages | ”Identify key points from section 3 of business_report.pdf, covering pages 33-37.” |
| Library-wide Metadata Inquiries | Asking about properties or aggregate statistics of multiple documents inside the library | ”How many documents talk about xx topic and list them in a table.” |
| Longform Text Generation | Writing extended text based on provided documents | ”Write a 5000 words literature review.” |