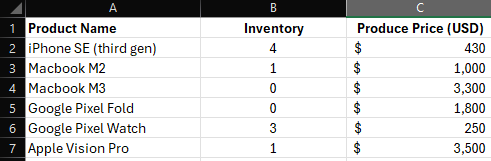

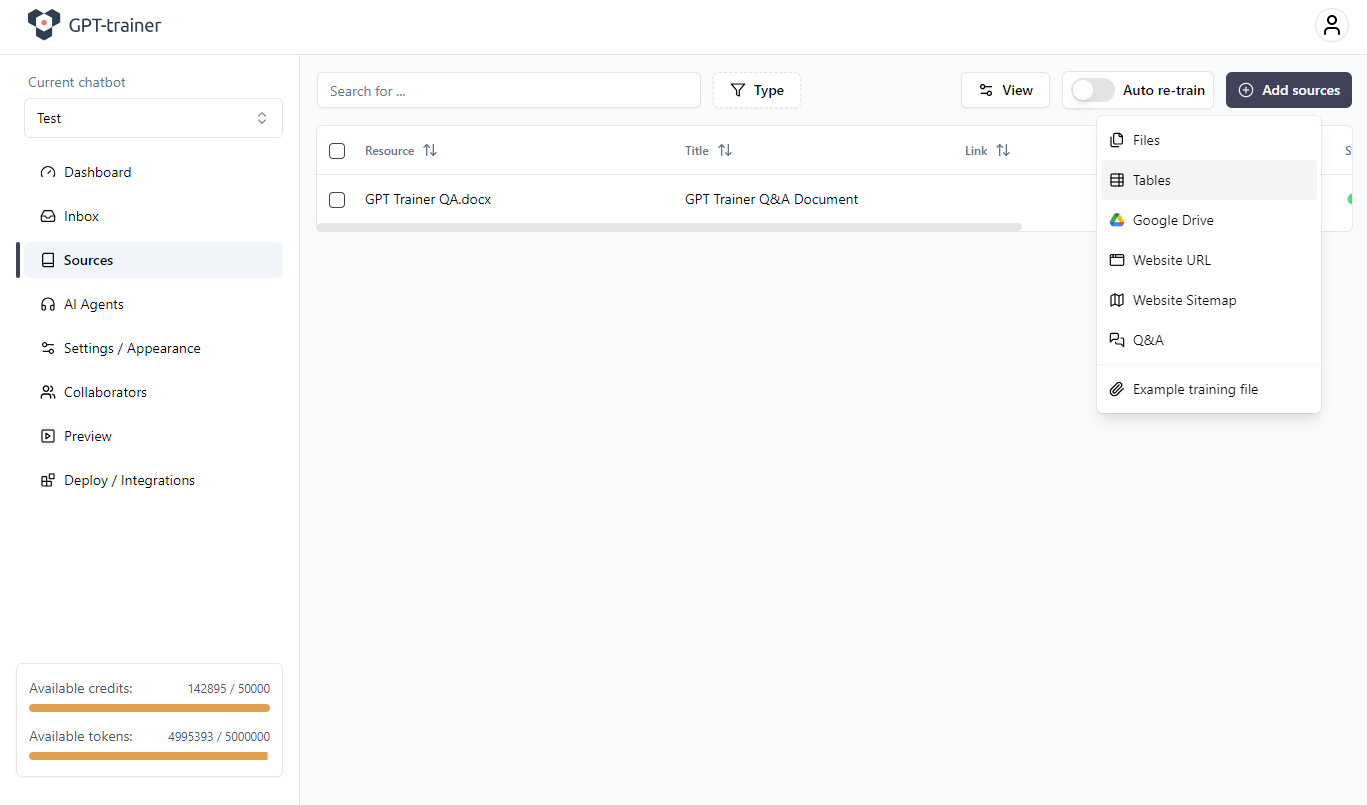

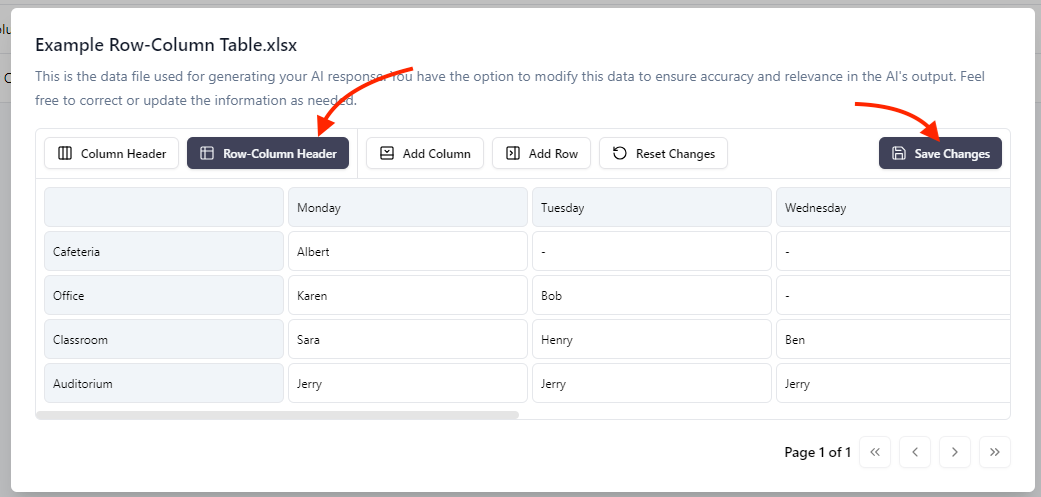
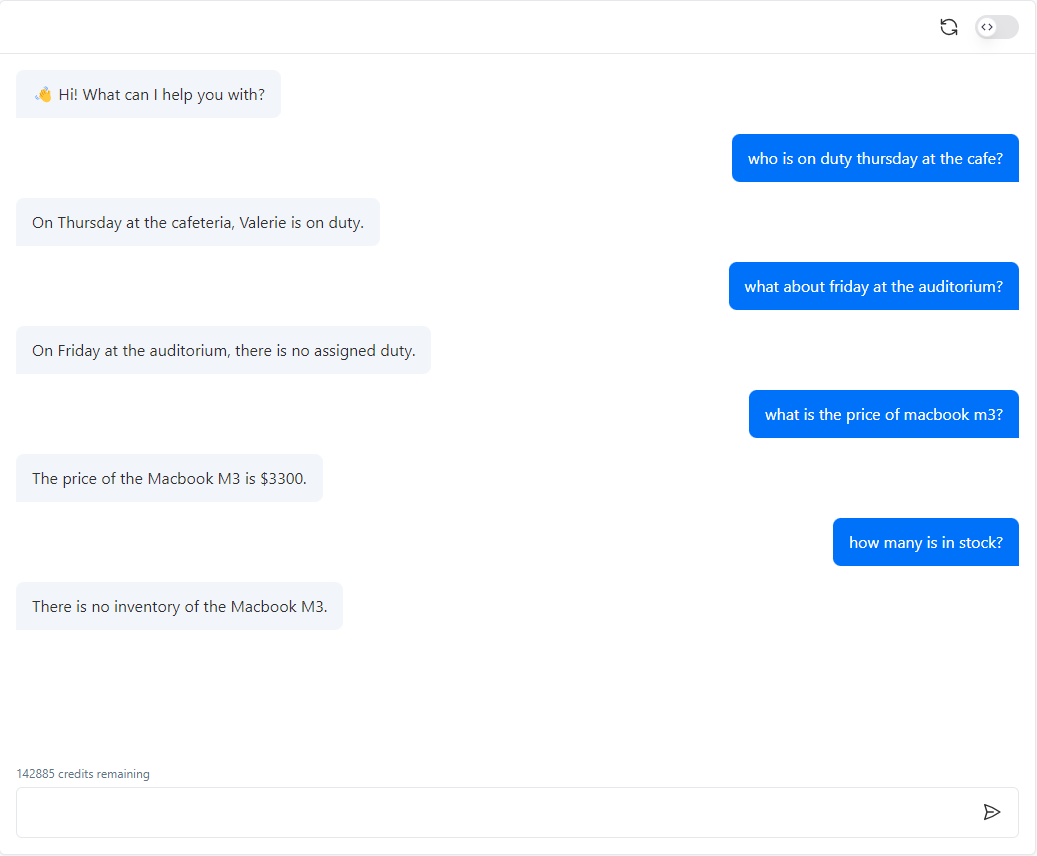
My Agent or chatbot doesn’t seem to understand or interpret my table correctly!
Large language models (LLMs) like GPT-4 are extremely adept at working with unstructured text data. With a multimodal training method, LLMs can even interpret visual or image data and associate it with natural language (like GPT-Vision). However, tabulated data is very different. There is no universal rule set or standard language patterns when it comes to representing structured information. Given the probabilistic nature of LLMs, they are not innately proficient at handling this type of data directly. An article from Microsoft Research recently evaluated GPT-4’s performance when processing structured data. Within it, model performance against numerous programmatic representations of structured data are discussed.